
Projects
Here are my PhD projects in chronological order.
VERITAS
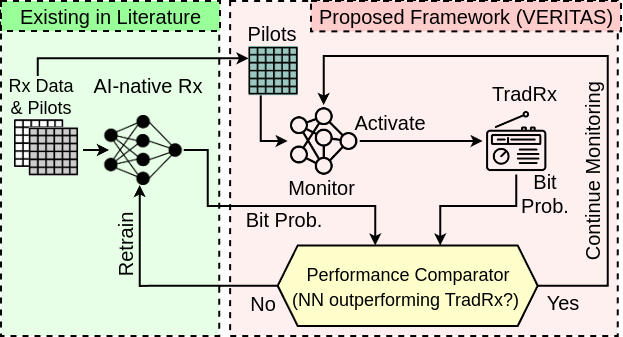
Abstract
- Publication: Nasim Soltani, M. Loehning, K. Chowdhury, “VERITAS: Verifying the Performance of AI-native Transceiver Actions in Base-Stations,” Available on ArXiv. pdf

UNICORN: URLLC Traffic Application Classification and OOD Detection in O-RAN
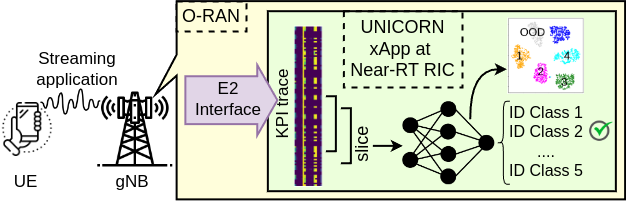
Resource allocation in 5G NR depends on the type of traffic for different users. Different applications are pre-categorized as different traffic types and the gNB follows these categories to orchestrate resources to different users that are running different applications. However, each application could have different delay or reliability requirements depending on the context and therefore, the pre-defined application to traffic type mapping might not precisely reflect application requirements in that specific context. This is why application classification instead of traffic type classification could help in finer-grained resource allocation. Furthermore, with the creation of new applications every day, gNB might encounter new applications that is it not previously trained to classify. In this case the gNB should be able to distinguish the new applications classes from the previously seen applications. Finally, all the known application classification and unknown application detection must happen by preserving privacy and without exposing user data. UNICORN proposes a joint classification and OOD detection pipeline for O-RAN compliant systems where 17 network key performance indicators (KPIs) are monitored to identify the application type.
- Publication: Nasim Soltani, D. LoPriore, J. Groen, K. Chowdhury, “UNICORN: URLLC Network Traffic Classification and OOD Detection for O-RAN,” IEEE International Conference on Machine Learning for Communication and Networking (ICMLCN), May 2025. pdf
- Dataset
- Code
- Poster presented at IEEE ICMLCN 2025, May 2025, Barcelona, Spain.
Learning From the Best: Deep Active Learning to Reduce the Labeling Cost
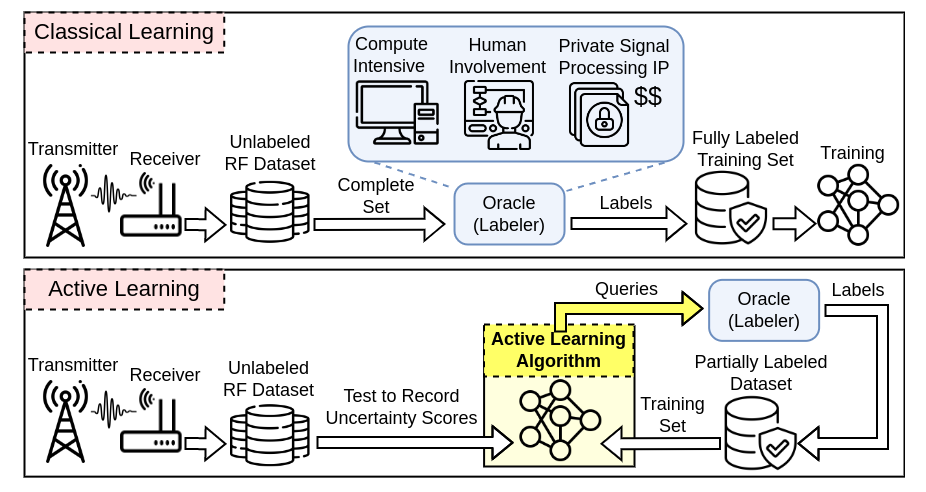
Collecting an over-the-air wireless communications training dataset for deep learning-based communication tasks is relatively simple. However, labeling the dataset requires expert involvement and domain knowledge, may involve private intellectual properties, and is often computationally and financially expensive. Active learning is an emerging area of research in machine learning that aims to reduce the labeling overhead without accuracy degradation. Active learning algorithms identify the most critical and informative samples in an unlabeled dataset and label only those samples, instead of the complete set. In this paper, we introduce active learning for deep learning applications in wireless communications, and present its different categories. We present a case study of deep learning-based mmWave beam selection, where labeling is performed by a compute-intensive algorithm based on exhaustive search. We evaluate the performance of different active learning algorithms on a publicly available multi-modal dataset with different modalities including image and LiDAR. Our results show that using an active learning algorithm for class-imbalanced datasets can reduce labeling overhead by up to 50% for this dataset while maintaining the same accuracy as classical training.
- Publication: Nasim Soltani*, J. Zhang*, B. Salehi, D. Roy, R. Nowak, K. Chowdhury, “Learning from the Best: Active Learning for Wireless Communications,” IEEE Wireless Communications Magazine, 31 (4), 2024. pdf
PRONTO: NNs In OFDM Receivers to Reduce Communication Overhead
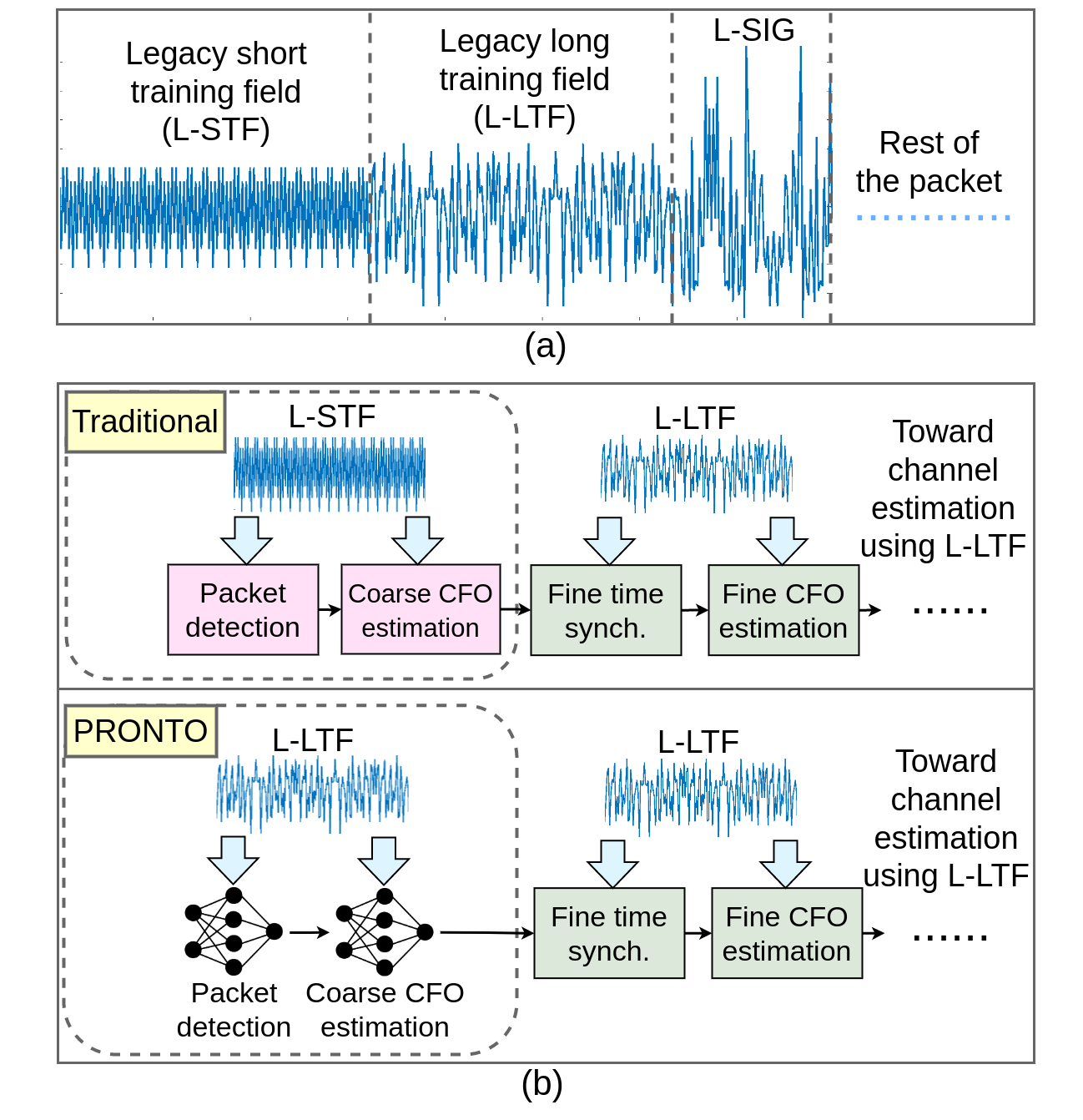
In IEEE 802.11 WiFi-based waveforms, the receiver performs coarse time and frequency synchronization using the first field of the preamble known as the legacy short training field (L-STF). The L-STF occupies upto 40% of the preamble length and takes upto 32 $\mu$s of airtime. With the goal of reducing communication overhead, we propose a modified waveform, where the preamble length is reduced by eliminating the L-STF. To decode this modified waveform, we propose a neural network (NN)-based scheme called PRONTO that performs coarse time and frequency estimations using other preamble fields, specifically the legacy long training field (L-LTF). Our contributions are threefold: (i) We present PRONTO featuring customized convolutional neural networks (CNNs) for packet detection and coarse carrier frequency offset (CFO) estimation, along with data augmentation steps for robust training. (ii) We propose a generalized decision flow that makes PRONTO compatible with legacy waveforms that include the standard L-STF. (iii) We validate the outcomes on an over-the-air WiFi dataset from a testbed of software defined radios (SDRs). Our evaluations show that PRONTO can perform packet detection with 100% accuracy, and coarse CFO estimation with errors as small as 3%. We demonstrate that PRONTO provides upto 40% preamble length reduction with no bit error rate (BER) degradation. We further show that PRONTO is able to achieve the same performance in new environments without the need to re-train the CNNs. Finally, we experimentally show the speedup achieved by PRONTO through GPU parallelization over the corresponding CPU-only implementations.
- Publication: Nasim Soltani, D. Roy, K. Chowdhury, “PRONTO: Preamble Overhead Reduction with Neural Networks for Coarse Synchronization,” IEEE Transactions on Wireless Communications, March 2023. pdf
- Poster presented at WIoT instituite industry day, May 2023, Boston, MA.
- Dataset, Code
Waldo: Deep Learning for Signal Detection and Time/Frequency Localization in the CBRS Band

Opening the Citizen Broadband Radio Service (CBRS) band in the US to secondary users offers unprecedented opportunities to LTE and 5G networks, as long as incumbent radar signals are protected from interference. Towards this aim, the US Federal Communications Commission (FCC) requires Environmental Sensing Capabilities (ESCs) to be installed along the coastal regions. Furthermore, FCC mandates that the secondary users transmit with low power levels, such that the aggregated interference and noise power in the vicinity of ESC sensors remains below -109 dBm/MHz. At this interference level, the ESC must detect 99% of radar pulses with peak power of at least -89 dBm/MHz. In this paper, we design an enhanced ESC sensor, called ESC+, that leverages the deep learning framework called `you only look once' (YOLO) for signal detection using spectrograms. We propose a two-stage spectrogram-based coarse and fine signal analysis method for: (i) detecting, and characterizing radar pulses in environments where the aggregated noise and interference level goes beyond FCC restrictions, and (ii) detecting and characterizing other signal types (e.g., 5G and LTE) in the CBRS band, with a goal of determining unauthorized users. We generate a realistic spectrogram dataset in MATLAB consisting of three signal types of radar, 5G, and LTE where the aggregated interference and noise power occurring concurrently with the radar pulse is varied upto -104 dBm/MHz. We show 100% radar pulse detection in interference and noise levels of up to 3 dB higher than what is required today.
- Publication: Nasim Soltani*, V. Chaudhary*, D. Roy, K. Chowdhury, “Finding Waldo in the CBRS Band: Signal Detection and Localization in the 3.5 GHz Spectrum,” IEEE GLOBECOM 2022. pdf
- Poster presented at AI-Edge annual meeting, Septermber 2022, Columbus, Ohio.
- Slides presented at IEEE GLOBECOM December 2022, Rio, Brazil.
- Dataset.
Other papers that I have co-authored on this topic:
- G. Reus-Muns, P. Upadhyaya, U. Demir, N. Stephenson, Nasim Soltani, V. K. Shah, K. R. Chowdhury, “SenseORAN: O-RAN based Radar Detection in the CBRS Band,” IEEE Journal on Selected Areas in Communications (JSAC), July 2023. link
- C. Tassie, A. Gaber, V. Chaudhary, Nasim Soltani, M. Belgiovine, M. Loehning, V. Kotzsch, C. Schroeder, and K. Chowdhury, “Detection of Co-existing RF Signals in CBRS using ML: Dataset and API-based Collection Testbed,” IEEE Communications Magazine Accepted May 2023. link
NN-key: NNs for Secure Communication
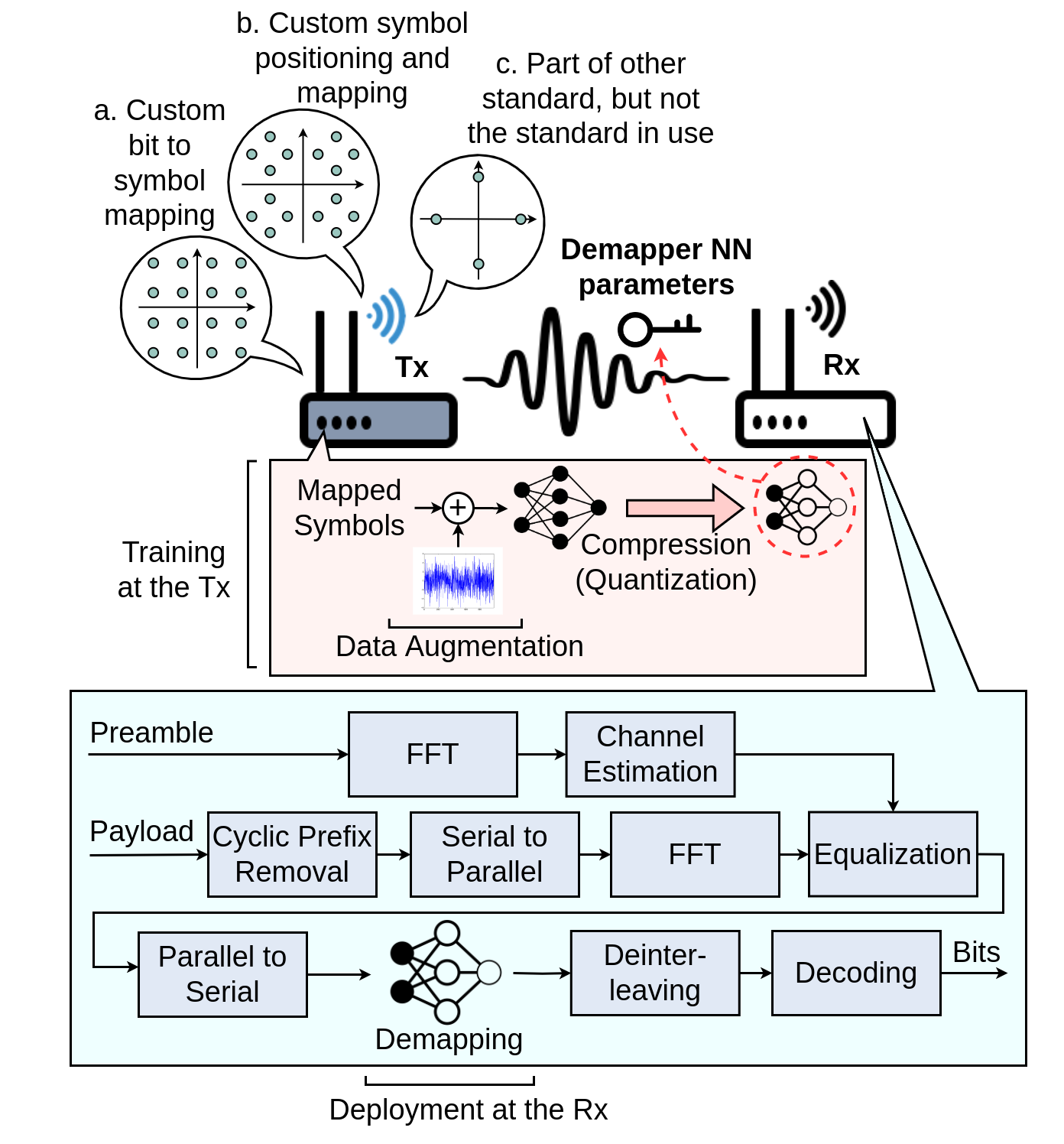
In this project, a demapper neural network is used to demap custom modulation schemes that are created and used for data transmission by the transmitter. As shown in the diagram on the side, the transmitter chooses a custom modulation scheme that (a) has a custom bit to symbol mapping, (b) has a custom symbol positioning and mapping, (c) is part of other standard, but not the standard in use, or a combination of the three. After modulating the coded symbol with the chosen scheme, the transmitter trains a demapper neural network with a step of data augmentation. This demapper learns to demap the noisy data symbols at the receiver-side to the original coded transmitted bits. During training, a step of quantization also happens to shorten the bit representation of the model weights and biases. After training, the transmitter sends the weights and biases of the trained model as a vector to the receiver, and the receiver uses those weights and biases to demap data symbols of future data packets.
- Publication: Nasim Soltani, Y, Li, D. Erdogmus, Y. Wang, and K. Chowdhury, “NN-key: A Neural Network-Based Secret Key for Demapping OFDM Symbols,” IEEE 19th annual Consumer Communications and Networking Conference (CCNC), 2022. pdf
- Slides Presented at IEEE CCNC, December 2021, virtual conference.
NNs In OFDM Receivers to Achieve Lower Bit Error Rate
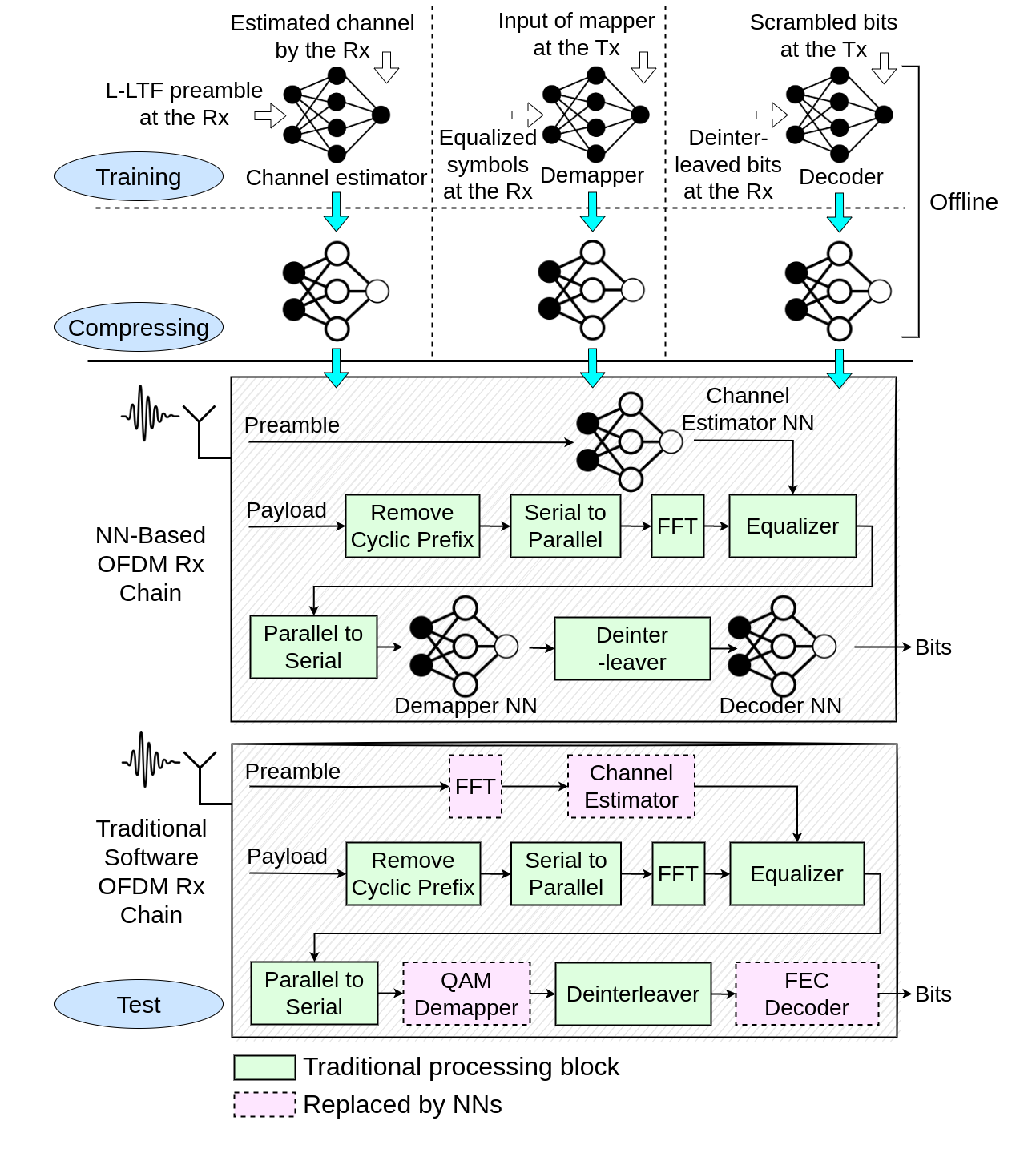
In this project, different components of channel estimator, demapper, and docoder in the orthogonal frequency division multiplexing (OFDM) receiver chain are replaced with properly designed and trained neural network. For the channel estimator we use a regressor neural network, with the training set collected from a low noise environment. During training, we use a data augmentation step of dynamically adding different levels of noise to the signal, so that the neural network learns to estimate channels in noisy environment too while the labels are accurate becaue they are from a low noise environment. We train the channel estimator with time-domain L-LTF preamble, so that our neural network replaces both the FFT and channel estimator block in the traditional chain. For the demapper we use a fully connected network that demaps one equalized sample to a series of bits at a time. The output size of the neural network depends on the modulation scheme and the problem is a multi-label classification problem. For the decoder neural network we use a neural network with gated recurrent units and formulate it as a multi-label classification problem. For the labels of the demapper and the decoder, we use the transmitter-side coded and uncoded bits, respectively, to help the networks learn the original transmit bits. Finally we use pruning and quantization methods to compress these neural networks to make them suitable for implementing an end to end OFDM receiver on the FPGA.
- Publication: Nasim Soltani, H. Cheng*, M. Belgiovine*, Y. Li*, H. Li*, B. Azari, S. D’Oro, T. Imbiriba, T. Melodia, P. Closas, Y. Wang, D. Erdogmus, and K. Chowdhury, “Neural Network-based OFDM Receiver for Resource Constrained IoT Devices,” IEEE Internet of Things Magazine 5 (3), pp. 158-164, 2022. pdf
Other papers that I have co-authored in this topic:
- B. Azari, H. Cheng, Nasim Soltani, H. Li, Y Li, M. Belgiovine, T. Imbiriba, S. D’Oro, T. Melodia, Y. Wang, P. Closas, K. Chowdhury, D. Erdogmus, “Automated deep learning-based wide-band receiver,” Computer Networks. 2022 Dec 9;218:109367. Link
RF Fingerprinting UAVs
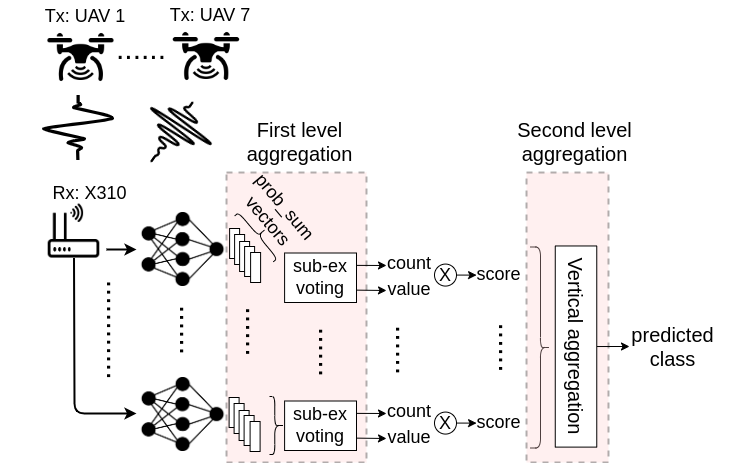
The universal availability of unmanned aerial vehicles (UAVs) has resulted in many applications where the same make/model can be deployed by multiple parties. Thus, identifying a specific UAV in a given swarm, in a manner that cannot be spoofed by software methods, becomes important. We propose RF fingerprinting for this purpose, where a neural network learns subtle imperfections present in the transmitted waveform. For UAVs, the constant hovering motion raises a key challenge, which remains a fundamental problem in previous works on RF fingerprinting: Since the wireless channel changes constantly, the network trained with a previously collected dataset performs poorly on the test data. The main contribution of this paper is to address this problem by: (i) proposing a multi-classifier scheme with a two-step score-based aggregation method, (ii) using RF data augmentation to increase neural network robustness to hovering-induced variations, and (iii) extending the multi-classifier scheme for detecting a new UAV, not seen earlier during training. Importantly, our approach permits RF fingerprinting on manufacturer-proprietary waveforms that cannot be decoded or altered by the end-user. Results reveal a near two-fold accuracy in UAV classification through our multi-classifier method over the single-classifier case, with an overall accuracy of 95% when tested with data under unseen channel. Our multi-classifier scheme also improves new UAV detection accuracy to a near perfect 99%, up from 68% for a single neural network approach.
- Publication: Nasim Soltani, G. Reus-Muns, B. Salehi, J. Dy, S. Ioannidis, and K. Chowdhury, “RF Fingerprinting Unmanned Aerial Vehicles with Non-standard Transmitter Waveforms,” IEEE Transactions on Vehicular Technology, Issue 12, Volume 69, 2020, pp. 15518-15531. pdf
- Dataset
Other papers I have co-authored on this topic:
- S. Mohanti, Nasim Soltani, K. Sankhe, D. Jaisinghani, M. DiFelice and K. Chowdhury, “AirID: Injecting a Custom RF Fingerprint for Enhanced UAV Identification using Deep Learning,” IEEE Globecom, 7-11 December 2020, Taipei, Taiwan. link
- J. Gu, Nasim Soltani, Y. Naderi, K. Chowdhury, “It’s a Bird, It’s a Plane, It’s ‘That’ UAV: RF Fingerprinting During Flight,” 55th Asilomar Conference on Signals, Systems, and Computers, pp. 300-304, 2021. link
More is Better: Channel-Resilient RF Fingerprinting through Data Augmentation

RF fingerprinting involves identifying characteristic transmitter-imposed variations within a wireless signal. Deep Neural Networks (DNNs) that do not rely on handcrafting features have proven to be remarkably effective in fingerprinting tasks, as long as the channel remains invariant. However, DNNs trained at a specific location and time perform poorly on datasets collected under different channel conditions. This paper proposes a data augmentation step within the training pipeline that exposes the DNN to many simulated channel and noise variations that are not present in the original dataset. We describe two approaches for data augmentation: The first approach is applied to the "transmitter data" when transmitter side data (i.e., pure signals without channel distortion) is available. The second approach is applied to the "receiver data", when only a passive dataset is available with already over-the-air transmitted signals. We show that data augmentation results in 75% improvement in the former case with a custom-generated dataset, and around 32-51% improvement in the latter case on a 5000-device WiFi dataset, compared to the case of non-augmented data fed to DNNs.
- Publication: Nasim Soltani, K. Sankhe, J. Dy, S. Ioannidis, and K. Chowdhury, “More is Better: Data Augmentation for Channel-Resilient RF Fingerprinting,” IEEE Communications Magazine 58 (10), 66-72, 2020. pdf
- Dataset
Other papers that I have co-authored on this topic:
- T. Jian, B. Costa-Rendon, E. Ojuba, Nasim Soltani, Z. Wang, K. Sankhe, A. Gritsenko, J. Dy, K. Chowdhury, S. Ioannidis, “Deep Learning for RF Fingerprinting: A Massive Experimental Study,” IEEE Internet of Things Magazine. 2020 Apr 13;3(1):50-7. link
- A. Al-Shawabka, F. Restuccia, S. D’Oro, T. Jian, B. Costa Rendon, Nasim Soltani, J. Dy, K. Chowdhury, S. Ioannidis, and T. Melodia, “Exposing the Fingerprint: Dissecting the Impact of the Wireless Channel on Radio Fingerprinting,” to appear in Proceedings of IEEE International Conference on Computer Communications (INFOCOM), Beijing, China ,2020. link
Modulation Classification on Smartphones

As spectrum becomes crowded and spread over wide ranges, there is a growing need for efficient spectrum management techniques that need minimal, or even better, no human intervention. Identifying and classifying wireless signals of interest through deep learning is a first step, albeit with many practical pitfalls in porting laboratory-tested methods into the field. Towards this aim, this paper proposes using Android smartphones with TensorFlow Lite as an edge computing device that can run GPU-trained deep Convolutional Neural Networks (CNNs) for modulation classification. Our approach intelligently identifies the SNR region of the signal with high reliability (over 99%) and chooses grouping of modulation labels that can be predicted with high (over 95%) detection probability. We demonstrate that while there are no significant differences between the GPU and smartphone in terms of classification accuracy, the latter takes much less time (down to $\frac{1}{870}$x), memory space ($\frac{1}{3}$ of the original size), and consumes minimal power, which makes our approach ideal for ubiquitous smartphone-based signal classification.